Dans un contexte de concurrence mondiale, d’innovations technologiques permanentes et d’accélération des délais, les consommateurs et les professionnels ont accès très rapidement à une offre de produits et de services abondante. Garantir la disponibilité du bon produit, au bon moment et au bon endroit est un challenge encore plus difficile pour la Supply Chain qui nécessite la prise en compte d’un nombre de facteurs quasi infini pouvant influencer la demande client : réseaux sociaux, nouveautés, concurrence, médias, événements politiques (Brexit, Hong-Kong, grèves…), évolutions de taux de change…
Dans ce monde VUCA (volatile, uncertain, complex, ambiguous), l’Intelligence Artificielle, avec des techniques comme le Machine Learning ou la capacité à apprendre et faire prendre des décisions à partir de la data, fournit des outils qui commencent réellement à améliorer les performances opérationnelles sur de nombreux maillons de la Supply Chain.
Nous avons voulu ici concrètement illustrer les apports et les challenges du Machine Learning dans la Supply Chain à travers 3 cas pratiques qui reflètent les 3 niveaux de la Supply Chain (stratégique, tactique et opérationnel) et représentent les grandes familles d’algorithmes (supervisés ou non supervisés, classification et régression).
L’IA dans la Supply Chain : des cas d’usage multiples et une boîte à outils d’algorithmes
Assistants personnels intelligents, reconnaissance faciale, chatbot, transports autonomes… L’Intelligence Artificielle révolutionne déjà nos vies et cette tendance est vouée à prendre de l’ampleur.
En entreprise, l’IA a également commencé à transformer plusieurs domaines d’activités : algorithmes de trading automatique, détection de fraude dans les assurances, maintenance prédictive sur les équipements industriels…
L’Intelligence Artificielle peut ainsi générer deux types de gains en Supply Chain :
/ L’amélioration du service au client (client B2C ou B2B) ou même le développement de nouveaux services
/ L’amélioration de la performance opérationnelle (productivité, qualité, stocks, fin de vie…)
Pour améliorer les performances de ces processus, l’Intelligence Artificielle en général, et le Machine Learning en particulier, proposent toute une panoplie d’algorithmes qui peuvent être utilisés, en fonction du besoin d’optimisation et de la typologie de données disponibles.
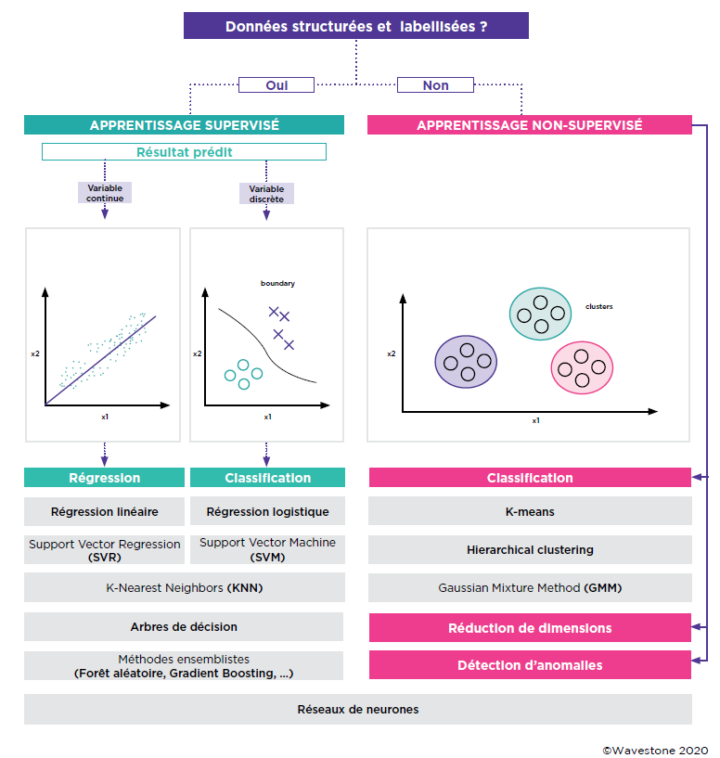
Cas 1 - Le « Store clustering » : du Machine Learning pour mieux capter les comportements clients en magasin
Le Store clustering (élaboration des groupes de magasins) est un processus clé dans le secteur du Retail qui permet de définir les magasins ayant des caractéristiques similaires et ainsi de pouvoir y affecter le bon assortiment. Un regroupement de magasins (le Cluster) doit être pertinent pour permettre de capter les différences de comportements d’achat des clients. Cela permet ainsi de mieux piloter les ventes, les marges et l’image de la marque.
Les similarités entre les points de vente peuvent concerner des axes très divers : surface du magasin, chiffre d’affaires, panier moyen, clientèle cible, familles de produits présentés, localisation du magasin : centre ville vs centre commercial, surface de vitrine, …
Le Store clustering utilise à la fois quantitativement et qualitativement :
• Le profil du magasin
• Les ventes de mix de produits
• Le profil client afin de construire des groupes de magasins avec des caractéristiques similaires.
Il est utile pour :
• L’achat des nouvelles collections
• La stratégie d’allocation et de réapprovisionnement du stock en magasins (initial set-up vs. replenishment vs. markdown)

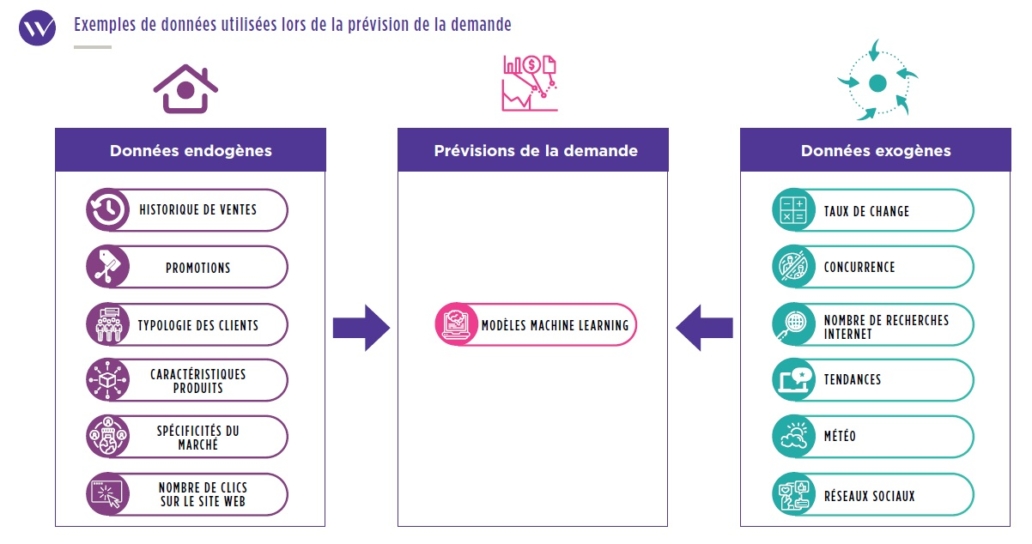
Cas 2 - Prévision de la demande : gagner en précision grâce au Machine Learning
Aujourd’hui, les anciens modèles de prévision (souvent fondés sur des moyennes historiques) sont dépassés
en termes de précision par de nouveaux modèles incorporant des algorithmes de Machine Learning. Ces nouveaux modèles permettent d’une part d’améliorer la précision des prévisions grâce à des algorithmes plus agiles et auto apprenants, mais aussi de traiter un volume de données plus important qu’avec les méthodes traditionnelles.
Une étape essentielle des projets de Machine Learning, en particulier dans les problèmes de prévision de la demande, est l’alimentation en données pertinentes et structurées.

Cas 3 - « Control tower » : passer d’un suivi réactif de la Supply Chain à une supervision proactive grâce à l’utilisation d’algorithmes de Machine Learning
La mise en oeuvre d’une Control tower en mode proactif nécessite plusieurs étapes :
- Obtenir une visibilité globale sur la Supply Chain par la connexion de tous les systèmes internes ou externes à l’entreprise (ERP, OMS, TMS, partenaires, véhicules connectés, capteurs météos…) ainsi que la captation et la mise à disposition des données fines des évènements.
- Détecter, traiter, voire même anticiper les alertes, grâce à des approches de segmentation et à l’utilisation d’algorithmes d’intelligence artificielle.
- Proposer des scénarios alternatifs en situation d’alerte ou en anticipation.
Ainsi, les algorithmes de Machine Learning de type réseau de neurones sont capables par exemple de distinguer les alertes de criticité haute (à transmettre aux équipes) des alertes de criticité basse (qu’il peut traiter automatiquement).
Méthodologie, écueils à éviter et recommandations
Pour réussir un projet d’IA, d’une manière générale, nous recommandons une approche en 2 grandes étapes :
/ Proof of Concept : Le plus simple est de démarrer par un Proof of Concept, sur un périmètre restreint, pour démontrer rapidement la valeur que peut apporter l’IA et définir quels algorithmes (ou combinaisons d’algorithmes) sont les plus pertinents par rapport au besoin et au jeu de données. Ces données pourront être enrichies au fur et à mesure, en commençant par les données internes à l’entreprise puis par des données externes.
/ Industrialisation : Dans un deuxième temps, la mise en place d’une organisation et de processus dédiés permettront de pérenniser la solution et d’élargir son périmètre d’action (cas d’usages étendus, nouvelles données, nouveaux périmètres…). Comme en phase de PoC, cette organisation devra faire collaborer les métiers de la Supply Chain et les data scientists.
C’est lors de cette étape d’industrialisation, que se pose la fameuse question du «make or buy» (développer la solution en interne ou acheter une solution de marché).

Mais les projets d’IA ne réussissent pas tous. Et ce pour différentes raisons. On peut évoquer bien sur les raisons classiques comme la mauvaise qualité de la donnée, une gouvernance des données inefficace, des métiers et SI trop silotés, un manque de compétences en data science, une adoption défaillante par les utilisateurs,..
Mais selon nous les 4 véritables écueils à éviter sont :
.. plutôt que sur du « Business Pull l’Intelligence Artificielle »… des solutions parfois brillantes qui arrivent au mauvais endroit au mauvais moment.
(startup, data science, foire, PoC, selfmarketing) mais ne pas porter l’effort sur le Dark side (data quality, engineering, architecture, RH et évolution des postes).
sans voir qu’ils sont forcément incompétents sur 90% d’un projet de valorisation de la donnée , et qu’il faut compléter leur savoir-faire par des compétences métiers/business de façon à être pleinement efficace.
en essayant de copier le premier de la classe plutôt que de valoriser ses propres assets grâce à son mindset naturel orienté sur la recherche d’optimisation et d’amélioration de la performance, la Supply Chain est un terrain de jeu extrêmement favorable pour l’Intelligence Artificielle, à condition d’aborder ces projets avec beaucoup de pragmatisme, des expertises combinées et un réel enthousiasme.
Insights liés



