Ces dernières années ont vu s’imposer l’intelligence Artificielle et l’industrialisation des algorithmes de Machine Learning au sein de tous les secteurs d’activité. Ces algorithmes, basés sur des méthodes d’apprentissage, nécessitent de nombreuses quantités de données afin d’exploiter pleinement leur potentiel. Pourtant, l’accès à ces données reste fortement limité au sein des organisations, et ce pour de multiples raisons :
- La donnée est réglementée voire classifiée : elle contient des éléments sensibles (données à caractères personnels par exemple), ce qui génère des risques (juridique, cyber, etc.), une difficulté d'exploitation (gestion des accès, etc.), et un coût pour l'organisation (mise en œuvre de dispositifs de protection informatique, mécanismes d'anonymisation, etc.).
- La donnée est difficilement accessible au sein de l’organisation, pour des raisons organisationnelles (fonctionnement en silos, etc.) ou techniques (complexité des formats et des flux, compatibilité des infrastructures, etc.).
- La donnée n’existe pas à date.
- Les volumes de données existants sont trop faibles pour les cas d'usages que l'on souhaite mettre en place.
- La donnée est trop coûteuse à acquérir ou à produire.
C’est notamment pour palier à ces irritants que les données synthétiques viennent apporter des solutions.
Qu'est-ce que la donnée synthétique, et à quoi sert-elle ?
Les données synthétiques sont des données générées artificiellement. Elles s’opposent ainsi aux données “réelles”, produites et collectées sur bases de processus et d’interactions, notamment sociales (recueil d’informations sur un client, par exemple).
L’objectif de ces données est de reproduire les propriétés d’un ensemble de données, grâce à une modélisation de leurs propriétés statistiques. L’algorithme génère de nouvelles données présentant les mêmes caractéristiques, tout en rendant impossible la reconstruction des données d’origine. Ainsi, ces données synthétiques présentent la même capacité prédictive tout en s’affranchissant des irritants listés ci-dessus.
Le concept de données synthétiques existe depuis les années 1990. C’est grâce à l’essor et l’industrialisation de l’IA qu’il a gagné en popularité, au vu de la nécessité d’avoir des jeux de données conséquents en taille et exploitables rapidement.
La problématique des données très sensibles
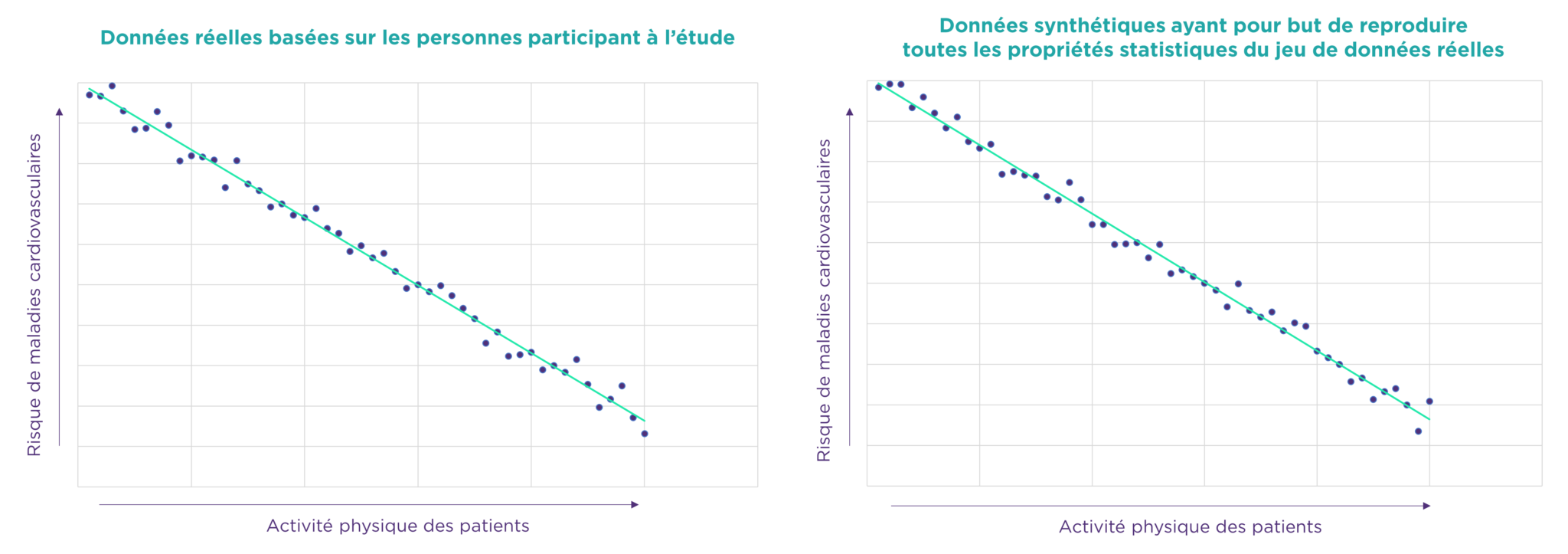
Illustrons par un exemple simple sur des données très sensibles, en l’occurrence des données de santé. Des chercheurs ont effectué une étude sur des dizaines de milliers de personnes visant à démontrer que l’activité sportive réduit les risques de maladies cardio-vasculaires. Afin de capitaliser sur ces données à des fins de réutilisation pour des études ultérieures, ceux-ci vont en générer des données synthétiques. Ces données pourront ainsi être conservées et partagées tout en évitant les contraintes réglementaires liées au jeu de données initial. Elles conserveront néanmoins toutes les caractéristiques statistiques du jeu de données initial (moyenne, écart-type, et caractéristiques plus complexes).
Les données synthétiques non structurées : le cas des deep fakes
Les données synthétiques peuvent également être des données non structurées. C’est par exemple le cas pour les travaux relatifs à la voiture autonome. La récente mise en lumière des deep fakes, notamment à des fins d’ingérence géopolitique, a également montré au grand public la puissance des « réseaux antagonistes génératifs » (les GAN), pouvant créer des images qui ressemblent à des photographies de visages humains, même si ces visages n’appartiennent à aucune personne réelle.




Ces quatre personnes n’existent pas : il s’agit de visages entièrement synthétisés.
Diverses techniques existent pour générer des données synthétiques
Plusieurs méthodes existent pour générer ces données, et dépendent de nombreux paramètres, notamment :
- Le nombre de dimensions et d'attributs à considérer pour les données.
- La complexité des relations entre ces attributs.
- Les ressources informatiques (e.g. puissance de calcul, briques IT de la plateforme de données) permettant de générer ces données.
- Les savoir-faire des collaborateurs.
- La taille du jeu de données que l'on souhaite obtenir.
- La vitesse à laquelle on souhaite avoir un jeu de données prêt (de plusieurs secondes à plusieurs semaines).
Il faut savoir qu’il n’y a pas de recette miracle et générique, et que chaque jeu de données va nécessiter de réfléchir aux méthodes à envisager.
Trois grandes familles de méthodes peuvent être mises en exergue
Ces données sont générées aléatoirement. De fait, elles ne possèdent pas de caractéristiques ou modèles statistiques calqués sur des données réelles. Elles visent à répondre à des besoins très simples et rapides.
Ces données sont générées selon des règles statistiques prédéfinies (par exemple, des bornes minimales et maximales, une moyenne, un écart-type ou de façon plus fine, par reproduction des distributions statistiques en prenant en compte les dimensions dépendant les unes des autres). Ces méthodes permettent de calquer des données réelles dans des cas relativement simples, tout en maîtrisant de potentielles aberrations que pourraient produire des modèles d’intelligence artificielle (“outliers”). Cependant, dès lors que les données gagnent en complexité, le savoir-faire mathématique nécessaire devient lui aussi complexe et le temps nécessaire pour développer ces modèles augmente.
Ces solutions, basées sur différents modèles d’apprentissage dont les réseaux de neurones, sont puissantes et permettent les utilisations les plus variées (enrichissement de jeux de données, génération d’image à partir de texte, création de deep fakes, etc.). Ce type d’algorithmes permet de générer des données sans nécessiter une maîtrise totale des caractéristiques et modèles statistiques des données réelles dont elles s’inspirent. Cependant, construire son propre réseau de neurones nécessite des capacités de calcul importantes, et les solutions open-source proposées sur le marché sont encore relativement rares.
Des méthodes plus ou moins puissantes et faciles à mettre en place
| Données entièrement fictives | Données générées par méthodes mathématiques | Données générées par Machine Learning | |
| Privacy by design | Oui | Oui | Oui |
| Réalisme des données | Faible | Variable selon le modèle mathématique | Fort à très fort, selon le jeu de données sur lequel on se base |
| Puissance de calcul | Nulle | Faible | Moyenne à forte |
| Difficultés techniques | Faibles | Moyennes à fortes | Moyennes à fortes |
| Compétences nécessaires | Faibles | Très importantes | Importantes |
Quels sont les gains apportés par les données synthétiques ?
La valeur ajoutée des données synthétiques est multiple :
- Gains financiers : les données synthétiques évitent à l'organisation d'acquérir des données externes, de devoir produire des données ou de mener des transformations parfois coûteuses sur des données existantes (chiffrement homomorphe, anonymisation, etc.).
- Souplesse réglementaire : les différentes contraintes (partage, durée de conservation, etc.) s'appliquant sur certaines données sensibles sont levées car les données synthétiques permettent de respecter l'anonymat et ne constituent plus de données à caractère personnel.
- Sécurité et accès à la donnée : tant qu'une donnée réelle est présente, il existe toujours un risque qu'elle soit compromise ou exposée. Les données synthétiques ne permettant pas de reconstruire le jeu de données réelles, elles permettent de tirer parti des informations du jeu de données tout en annihilant les risques sur les données qui sont remplacées.
- Agilité et collaboration : exit le parcours du combattant pour accéder aux données, les modalités d'exposition sont simplifiées, entraînant un partage facilité et une collaboration plus aisée entre différentes organisations.
- Innovation : l'utilisation de données synthétiques permet l'entraînement intensif des algorithmes d'IA et fait émerger de nouveaux usages.
Des cas d'usages concrets et diversifiés dans chaque secteur d'activité

Assurances : gestion du risque et pricing des offres
→ Synthèse d’un jeu de données géographiques visant à reproduire la répartition des logements sur le territoire, et liaison avec des données météorologiques afin d’améliorer la gestion du risque et la performance des modèles de pricing.

Retail : go-to-market vers un nouveau pays
→ Génération d’un jeu de données clients visant à simuler le comportement de clients d’un pays A en se basant sur les données réelles d’un pays B et des différences de comportements entre les deux pays. Il s’agit ici d’un exemple d’application du transfert de style, où l’utilisation des donnée synthétiques est à des fins de prédiction de ventes et d’atteintes des objectifs d’expansion internationale.

Banque : capitalisation sur des données provenant de différentes entités bancaires
→ Utilisation de données synthétiques visant à faciliter l’échange de données entre différents corps de métiers d’un groupe bancaire répartis sur plusieurs continents, pour lesquels les législations diffèrent en termes de réglementation des données personnelles.

Secteur public : détection de la fraude et du blanchiment d’argent
→ Mise en œuvre de la data augmentation afin d’entraîner fortement les algorithmes de détection, dans le but de contrer toutes les techniques de fraudes qui se basent elles aussi sur l’IA pour se sophistiquer et passer entre les mailles du filet. Les comportements frauduleux étant en général rares et noyés dans les comportements non frauduleux, ces techniques peuvent permettre de ne pas les négliger durant la phase d’apprentissage des algorithmes.

Santé : augmentation d’un échantillon de données de patients pour entraîner un modèle d’IA
→ Augmentation synthétique de l’échantillon de données obtenues lors des tests sur les patients afin d’améliorer l’apprentissage des algorithmes et de faciliter l’accès à des données de santé désormais complètement anonymes.

Audiovisuel : utilisation de deep fakes
→ Utilisation de deep fakes visant à générer de nouveaux visages, à augmenter les possibilités d’effets spéciaux, à faciliter les doublures, voire même à optimiser la traduction en langues étrangères grâce à la synchronisation des lèvres. Ce sont les mêmes techniques qui, de l’autre côté, contribuent à la génération et à la diffusion de fake news.
Plusieurs de ces cas d’usage ne sont pas nécessairement cantonnés à un secteur en particulier et peuvent être appliqués dans chaque industrie. Notamment, des cas classiques peuvent être mis en place de façon universelle, telle que la synthèse de jeux de données clients destinés à faciliter la phase de recette et à accélérer le CICD dans une approche DevOps (par ailleurs, les réglementations européennes sur la protection des données ont récemment entraîné des amendes auprès d’entreprises pour avoir utilisé des données à caractère personnel de production en phase de test).
Bonnes pratiques à adopter pour se lancer dans ce type de projet
Gartner estime qu’en 2024, 60% de la donnée utilisée pour le développement des projets d’IA et d’Analytics seront des données de synthèse. Tous les secteurs vont naturellement se lancer dans ces projets afin d’en tirer la valeur ajoutée décrite précédemment.
Afin de mener à bien un projet de génération de données synthétiques, quelques pratiques sont privilégiées :
Cela permet de faciliter l’engagement de ce type de projets et de convaincre de leur intérêt.
- Un fort sponsorship est nécessaire car ce type de projets peut nécessiter des investissements en temps et en formation afin d’obtenir le savoir-faire nécessaire à leur réussite.
- Plus globalement, la sensibilisation des métiers et des profils non techniques à la data permet de fournir un socle de connaissances permettant de prendre connaissance de l’arsenal des possibilités pour contourner des contraintes techniques et/ou réglementaires, et faciliter ainsi l’innovation et l’émergence d’idées.
Notamment :
- Les équipes allant produire ces données.
- Les métiers et les data scientists et analysts ayant vocation à les consommer.
- Les équipes IT fournissant les outils et plateformes permettant la mise en œuvre.
- Les équipes juridiques et réglementaires afin de lever tout risque dès le début du projet.
Il s’agit de vérifier que le jeu de données sur lequel va s’appuyer la création de données synthétiques (le cas échéant) n’est pas biaisé. À défaut, le biais sera reproduit et la valeur ajoutée des données de synthèse sera limitée.
L’objectif est de vérifier que les données générées ne sont pas biaisées et présentent des résultats fidèles aux données réelles le cas échant. Cela passe par :
- La définition des KPIs qui permettront de définir dès le départ quelles sont les conditions que doivent respecter les données de synthèse, et qu’on mesurera après leur synthèse.
- Des vérifications simples et rapides sont à systématiser afin de gagner du temps en cas d’imprécision du modèle (valeurs aberrantes, calculs simples type moyennes ou écarts types pour des données chiffrées par exemple).
Les entreprises ont aujourd’hui acquis une bonne maturité pour évaluer le caractère confidentiel des données, par l’intermédiaire du rôle de DPO notamment, qui combine fréquemment des compétences à la fois réglementaires et technologiques. Il est donc préconisé d’impliquer le DPO dans les travaux afin qu’il puisse comprendre comment ces données ont été générées, par quels mécanismes, et qu’il certifie que ces mécanismes garantissent bien l’anonymat.
- En particulier, documenter les données, les décrire et les renseigner dans les outils de data management permet leur pérennité et facilite leur réutilisation.
- Il s’agit aussi de responsabiliser les équipes vis-à-vis de cette donnée en mettant en œuvre le rôle de data owner, pour officier durant le cycle de vie de cette donnée.
En synthèse (c'est le cas de le dire...)
→ Les données synthétiques représentent un levier fort pour générer de la valeur tout en limitant les contraintes liées à la donnée.
→ Leur utilisation va s’intensifier sur les années à venir et les organisations auront pour enjeu d’acquérir les savoir-faire et l’expérience nécessaires.
→ Les cas d’usage sont multiples et concernent chaque secteur, avec une valeur ajoutée encore plus forte lorsqu’on traite de données classifiées.
→ Les organisations qui sauront maîtriser le potentiel de ces données auront fait un pas de plus vers leur démarche data-driven.
Insights liés



